
DeepSeek, a Chinese artificial intelligence company based in Hangzhou, has fundamentally disrupted the expensive world of large language models (LLMs) by revealing technical innovations that dramatically reduce training costs without sacrificing performance.
Most shockingly, the company revealed that training its sophisticated R1 reasoning model, a model that performs at the level of OpenAI’s most advanced systems and was trained for approximately $294K using 512 Nvidia H800 chips.
- Understanding the Foundation: What Are Transformers and Why Do They Matter?
- How Transformers Process Text: From Input to Output
- The Hidden Problem: The KV Cache Bottleneck Nobody Talks About
- DeepSeek’s Breakthrough #1: Multi-Head Latent Attention (MLA)
- KV Cache Problem vs DeepSeek’s MLA Solution
- DeepSeek’s Breakthrough #2: Mixture of Experts (MoE) Architecture
- Mixture of Experts: DeepSeek’s Efficient Expert Selection
- DeepSeek’s Breakthrough #3: Multi-Token Prediction
- The Cost Breakdown: Why Is DeepSeek So Much Cheaper?
- Why This Matters: The Democratization of AI
- The Technical Elegance Behind Cost Reduction
- What’s Next? The Future of Efficient AI
- Why This Matters to You
- Searching for Meaning in the Vastness of Cosmos
- FAQs
To put this in perspective, OpenAI’s Sam Altman stated that training GPT-4 cost over $100 million. If you’re puzzled by how this is possible, you’re not alone and that’s exactly what we’re going to explore in detail through this article!
Understanding the Foundation: What Are Transformers and Why Do They Matter?
Before we can appreciate DeepSeek’s brilliant innovations, we need to understand the basic building blocks of modern AI. Think of a transformer as an incredibly sophisticated reading comprehension system. When you ask ChatGPT or Claude a question, the transformer model inside breaks down your question into tiny pieces called tokens (roughly equivalent to words or word fragments) and converts them into numbers that the computer can understand.
What makes transformers revolutionary is their “attention mechanism”. Imagine having the ability to simultaneously understand how every word in a sentence relates to every other word. This differs from older AI systems such as RNNs that had to read words one-by-one sequentially, like a person reading left-to-right.
Transformers can read everything at once, processing an entire sentence or even an entire book in parallel, making them dramatically faster.
How Transformers Process Text: From Input to Output
The attention mechanism works by assigning “attention scores” to each word based on its relevance to other words. For example, in the sentence “The bank’s financial reports were detailed,” the word “bank” needs to pay careful attention to “financial” and “reports,” but less attention to “the” or “were.” These attention scores help the model understand context, which is essential for generating intelligent responses.
The Hidden Problem: The KV Cache Bottleneck Nobody Talks About
Here’s where things get interesting… and expensive. Every time an AI model generates a response, it needs to remember information about tokens it has already processed. Specifically, it stores something called the KV cache (Key-Value cache), which contains compressed representations of previous words called “keys” and “values”.
Imagine you’re having a multi-turn conversation with an AI chatbot. With each new message you send, the model must load all previous keys and values from memory to understand the context of your earlier messages.
As your conversation grows longer, this cache becomes massive, consuming enormous amounts of GPU memory. In extreme cases, for a large model processing long documents, the KV cache can, in extreme long-context scenarios, grow to several times the size of the model’s weights.
This creates a severe bottleneck because modern GPUs have limited memory, and moving data between storage and the GPU takes far more energy and time than the actual computations.
| Model | Reported Run Cost | Estimated Total Infrastructure |
| GPT-4 | $100M+ | $10B+ |
| DeepSeek R1 | $294K | $1.3B |
The traditional approach to handling this was to compromise and use fewer attention heads or use smaller models. But DeepSeek found a better way, so what is it?
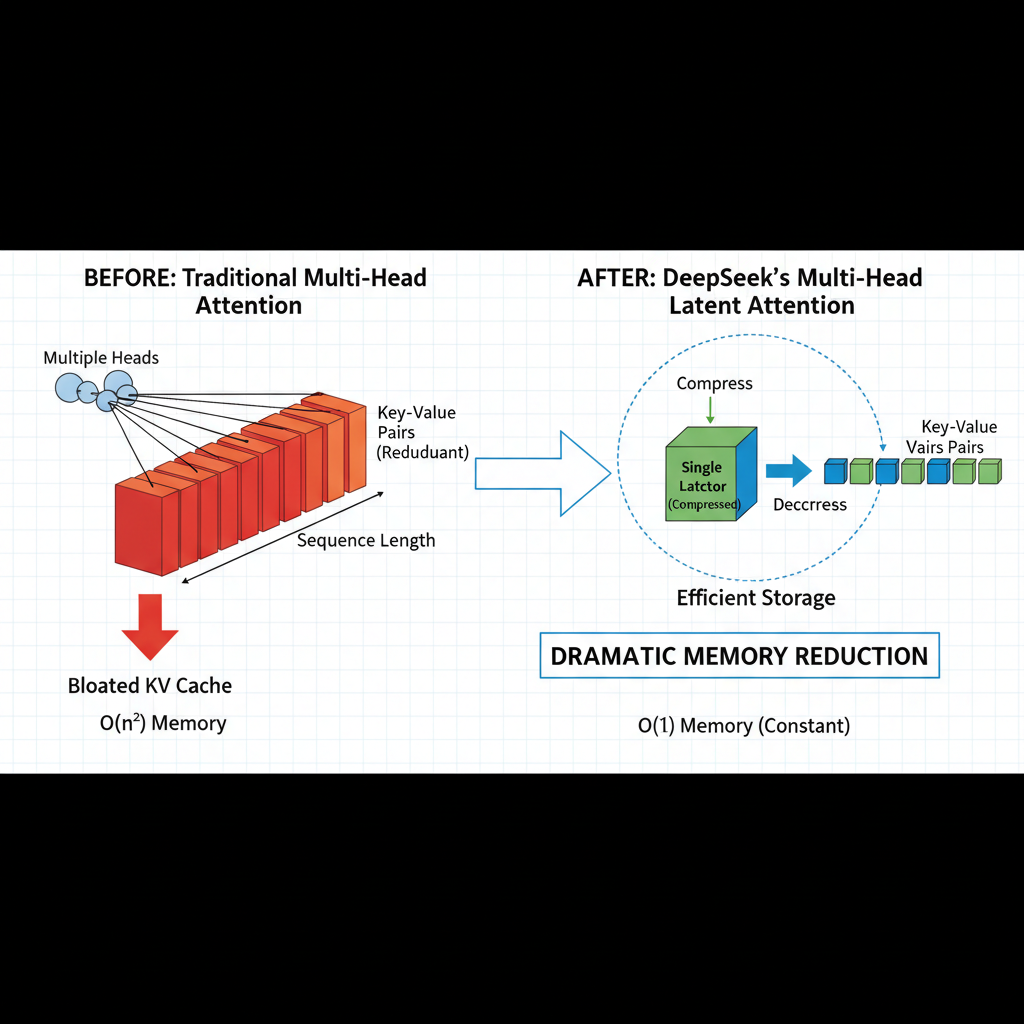
DeepSeek’s Breakthrough #1: Multi-Head Latent Attention (MLA)
This is where DeepSeek’s genius shines. Instead of storing massive key-value matrices for each attention head, they invented Multi-Head Latent Attention (MLA), a technique that compresses the KV cache dramatically while maintaining model quality.
Here’s the clever trick: instead of caching the full keys and values separately for each of the many attention “heads” (multiple processing paths), MLA stores a single, compressed latent vector per token.
This latent vector is roughly 1/13 to 1/5 the size of traditional KV caches (about 8–20%). When needed, this tiny latent vector is decompressed on-the-fly to create the keys and values for each head.
KV Cache Problem vs DeepSeek’s MLA Solution
Think of it like this: instead of storing 100 detailed photographs, you store a single small compressed file that can be expanded into 100 detailed photographs whenever you need them. The expansion process requires a bit more computation, but because memory bandwidth (moving data around) is the real bottleneck in AI inference, trading computation for memory savings is brilliant.
In practical terms, MLA reduces the KV cache to just 5-13% of traditional methods, meaning models can handle much longer conversations and documents without running out of memory. This also enables faster token generation because the GPU spends less time fetching data from memory.
DeepSeek further optimized MLA by using something called “Rotary Position Embeddings (RoPE)” with a decoupled design, essentially encoding position information in a separate, efficient way rather than redundantly across all heads.
DeepSeek’s Breakthrough #2: Mixture of Experts (MoE) Architecture
The second major innovation is Mixture of Experts, a technique that dramatically reduces computation without reducing intelligence. Imagine you have a team of specialists: a mathematics expert, a programming expert, a philosophy expert, and so on.
Rather than having one generalist handle every question, you route each question to the appropriate expert or combination of experts.
Mixture of Experts: DeepSeek’s Efficient Expert Selection
DeepSeek-V3 reportedly has around 671 billion total parameters but only 37 billion are “active” (actually used) for any single input. Here’s how it works: a “gating network” looks at your input and decides which expert networks should process it.
For a math problem, it activates the math experts. For code, it activates the coding experts. This means the model is fundamentally more efficient because it’s not forcing all 671 billion parameters to work on every task.
A crucial improvement DeepSeek made is solving the “load balancing” problem that plagued earlier MoE systems. Previously, some experts would become over-utilized while others sat idle, creating inefficiency. DeepSeek introduced dynamic load balancing and shared experts that are always active, ensuring all experts are used effectively.
This is like having a dispatcher who intelligently routes work to keep all team members busy instead of letting some stand around idle.
DeepSeek’s Breakthrough #3: Multi-Token Prediction
Most AI models predict one token at a time. During training, for each position in the text, the model predicts the next single token. DeepSeek realized they could predict multiple tokens simultaneously, essentially teaching the model to predict the next two tokens in a single forward pass.
During training, this enables more efficient learning. During inference (when the model is actually responding to you), the model can reuse high-confidence predictions to reduce redundant computation during decoding. This dramatically speeds up response generation with minimal accuracy loss.
The Cost Breakdown: Why Is DeepSeek So Much Cheaper?
We must be honest about the “cheapness” narrative. While DeepSeek’s reported $294,000 training cost for R1 sounds shockingly low, the full picture is far more nuanced.
The company acknowledges that this figure represents only the final training run. It excludes the years of foundational research, failed experiments, and the massive infrastructure development that made that final run possible.
Researchers estimate that DeepSeek’s total infrastructure investment (GPU cluster capital expenditure alone) is around $1.3 billion, with annual operating costs approaching $100-500 million annually when you factor in personnel, electricity, cooling, and maintenance.

(Image Source: What Is DeepSeek? Everything a Marketer Needs to Know)
However, the key distinction is that by amortizing costs across many models and using their efficient architecture, the incremental cost to train individual models like V3 is dramatically lower than Western equivalents.
For comparison, researchers estimate GPT-4o costs around $10 million to train, while Claude 3.5 Sonnet costs approximately $30 million. DeepSeek achieves comparable or superior performance with a fraction of these incremental costs.
The real advantage comes from a combination of factors:
- highly optimized engineering that leaves no compute on the table
- custom GPU communication protocols to work around chip export restrictions
- partial 8-bit native training to reduce memory usage
- the architectural innovations we discussed above
- access to cheaper computational resources.
Why This Matters: The Democratization of AI
DeepSeek’s achievement is historically significant because it demonstrates that frontier-grade AI doesn’t require tens of billions of dollars.
The company proved that with brilliant engineering, smart architectural choices, and efficient resource management, a well-coordinated team can build state-of-the-art models even under significant hardware constraints.
This has implications across multiple dimensions:
For researchers and smaller organizations
Open-source models like DeepSeek V3 (which are freely available) mean that advanced AI capabilities are no longer locked behind API paywalls controlled by a handful of mega-corporations. Any team with adequate compute resources can now build powerful applications using these models.
For the AI industry
The competitive pressure is immense. Meta, OpenAI, Google, and others can no longer rely on brute-force compute advantages. The engineering details matter now more than ever.
For efficiency standards
DeepSeek’s technical report is a masterclass in optimization. Other AI labs are already studying their techniques, and many are implementing similar architectures. This will likely accelerate the decline in training costs industry-wide.
For geopolitics
DeepSeek’s success despite US chip export restrictions demonstrates that the US dominance in AI capability cannot be assumed to be permanent. This has prompted serious discussion among policymakers about the future of AI development and competition.
The Technical Elegance Behind Cost Reduction
DeepSeek’s brilliance lies not in eureka moments, but in a masterful synthesis of existing concepts. For example, their Multi-Head Latent Attention (MLA) is a sophisticated evolution of established Group-Query Attention (GQA) research.
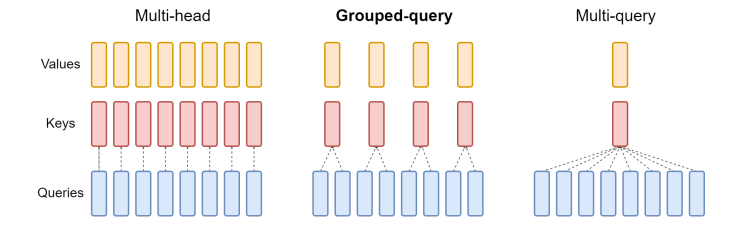
The true genius is found in the integration, the careful layering of small engineering wins to create a system far more efficient than the sum of its parts.
Compounding Efficiency
Consider their approach to memory optimization. By layering several strategies, DeepSeek achieves compounding returns:
- Precision: Utilizing 8-bit precision instead of standard 16 or 32-bit formats.
- Architecture: Strategically placing layer normalizations and refining attention masking.
- Processing: Implementing highly efficient tokenization.
While each of these adjustments individually offers a 10–20% gain, their intelligent combination compounds into a massive 70–80% saving in total resource metrics.
Infrastructure as a Competitive Edge
The infrastructure optimizations are equally vital. To overcome the bandwidth bottlenecks of the H800 GPU, the team developed custom communication protocols, precise pipeline parallelism to eliminate idle time, and thoughtful batching strategies.
Executing this requires more than just coding skill; it demands an intimate synchronicity between the algorithm and the hardware, a feat only achievable by a highly specialized team capable of bridging the gap between math and silicon.
What’s Next? The Future of Efficient AI
DeepSeek’s innovations are already being adopted. Meta’s Llama 3.3 model incorporates similar efficiency improvements. Researchers worldwide are implementing MLA in their models. The cost of training state-of-the-art models will continue declining, but we’re not at “free” yet.
The trajectory suggests that within 2-3 years, the actual incremental cost to train a frontier model similar to DeepSeek V3 could drop to $1-5 million as tooling improves and techniques become standardized. This democratizes AI development. A well-funded startup could plausibly train a frontier model for less than they’d pay for Series B office space in San Francisco.
However, challenges remain. Electricity costs for massive GPU clusters are already significant and will only grow. Data acquisition and curation require expertise. Talent remains expensive. But the era where AI advancement was locked behind trillion-dollar capital expenditures is clearly ending.
Why This Matters to You
DeepSeek’s architecture innovations aren’t just academic exercises, they represent a fundamental shift in how we approach AI engineering. By addressing the real bottlenecks (memory bandwidth, compute efficiency, load balancing), rather than throwing more GPUs at problems, they’ve created something simultaneously cheaper, faster, and more capable than the alternatives.
The Multi-Head Latent Attention mechanism elegantly solves the KV cache bottleneck that plagues all transformer models. The improved Mixture of Experts architecture ensures that computational capacity scales effectively with capability. Multi-token prediction accelerates generation without sacrificing accuracy.
For the industry, this means the intense competition for AI capability is shifting from a capital expenditure arms race to an engineering talent and optimization arms race. For users like you, this means more capable open-source models, lower API costs as companies compete, and AI capabilities that can run on smaller hardware. For society, it means AI technology is diffusing faster across organizations of all sizes.
Searching for Meaning in the Vastness of Cosmos
Since we’re discussing breakthroughs here, you must often wonder about the asymmetry of this world where some have to struggle through several hardships while some live a very comfortable life.
We also ponder over questions about the creation of the universe as it’s something which has always fascinated us but we could never really get a conclusive answer.
We’re still a tiny rock in this vastness of cosmos, relentlessly searching for a meaning to life. This is exactly where Sant Rampal Ji Maharaj steps in!
He provides the answers to all your questions in detail, and of course while taking references from our very own holy scriptures which our religious gurus could never decipher properly.
Do watch this detailed video on the Creation of Universe by Sant Rampal Ji and you can always find more satsang discourses by searching up “Sant Rampal Ji Maharaj” on Youtube or just download the ‘Sant Rampal Ji Maharaj’ Mobile App! Human life is precious and no one should miss out on this revelation.
FAQs
1. How much did it actually cost to train DeepSeek R1?
While the final training run for DeepSeek R1 cost approximately $294,000, the total investment is much higher. This figure does not include millions spent on the foundational V3 model or the estimated $1.3 billion invested in GPU infrastructure and years of R&D.
2. What is Multi-Head Latent Attention (MLA) and how does it save money?
MLA is a breakthrough that solves the “KV Cache” bottleneck. Instead of storing massive amounts of data for every word in a conversation, it compresses that data into a tiny “latent vector.” This reduces memory usage by up to 90%, allowing the AI to process longer conversations faster and on cheaper hardware.
3. Is DeepSeek R1 better than GPT-4?
In many reasoning and coding benchmarks, DeepSeek R1 performs at or above the level of GPT-4o and Claude 3.5 Sonnet. Its primary advantage is efficiency; it achieves this high performance using significantly fewer “active” parameters and lower computational power.
4. How does the Mixture of Experts (MoE) architecture work in DeepSeek?
DeepSeek-V3 uses a “specialist” approach. Although the model has 671 billion total parameters, it only activates about 37 billion for any single task. A gating network routes your question to the most relevant “experts” (e.g., math or coding specialists), saving massive amounts of compute.
5. Can I use DeepSeek for free?
Yes. DeepSeek models are often released under permissive open-weight licenses (like MIT), meaning developers can download and run them on their own servers for free. Additionally, DeepSeek’s API is significantly more affordable than competitors, often costing 20x to 100x less per million tokens than GPT-4o.






